![[PREV]](prev.gif)
![[PREV]](next.gif)
![[PREV]](toc.gif)
Galapagos was written using Microsoft Visual C++, and is designed to
run under Windows 95. We chose Windows 95 because it seems to have the
largest potential Galapagos users base. The following sections describe
some implementation details of Galapagos.
The SCM interpreter we used as a base is written in C. Most of the original
code we added was written in C++. The parts we used from SCM are almost
identical to the original. In fact, by changing the scmconfig.h file (which
contain machine-specific configuration) and #defining THREAD to be null,
the C files should become equivalent to the sources we used.
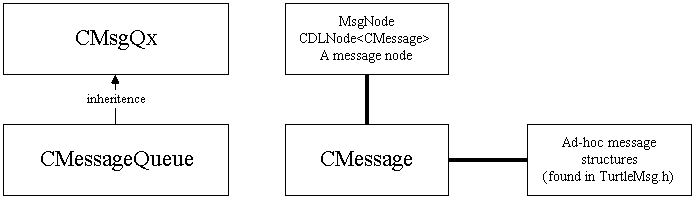
We have implemented two MT-safe FIFO message queue classes. Both will
block when trying to read from an empty queue. CMsgQx, the extended
message queue, supports the same interface as the one provided in Scheme,
plus an additional support for "Urgent Messages". These take
precedence over all other messages. CMessageQueue is message queue
with exactly the same interface as the Scheme level message queues, but
which contain internal logic to handle "Urgent" messages used
to deal with cases where synchronous respond is needed, such as I/O, Garbage
collection, and Scheme-level inter-thread communications.
Galapagos is based on SCM, which is a single-thread, read-evaluate-print-loop
(repl) based Scheme interpreter. The most important issue in migrating
SCM was how to maintain the interpreter's natural repl-based approach,
yet allow for multiple threads to interact, and for Windows messages to
be processed quickly.
We used WIN32's multithreading capabilities to solve these problems.
A single thread handles all aspects of the GUI - in a sense, "all
that is Windows": graphic boards, turtles, consoles, menus and so
on. Each interpreter runs in a thread of its own, interacting with the
GUI using a message queue similar to the one provided at the Scheme level.
The GUI thread manages both commands received from the OS and from the
different interpreters running on their own threads. To ensure as fast
responses as possible, priorities are used: OS messages (such as windows
updates and input devices) gets highest priority; Console (text messages)
come second, and graphics messages are last. This allows the interpreters
to run interactively in a satisfactory manner.
SCM interpreter threads each run in the old-fashion repl mode. When
a computation is over, the interpreter blocks until new input comes from
the GUI thread. All blocking functions were modified to allow synchronous
messages (such as the one generated by tell-thread) to work. In
addition, SCM's "poll routine" is used to force checking for
such messages even during computations.
An additional thread is used for Garbage Collection. It is described
in detail in the section dealing with garbage collection.
In this section we will briefly describe SCM's garbage collector, and
then discuss the modifications done to adapt it to Galapagos's multithreading
computations. It should be noted that the garbage collector used is a portable
garbage collector taken from "SCHEME IN ONE DEFUN, BUT IN C THIS TIME",
by George J Carrette.
SCM uses a conservative Mark & Sweep garbage collector (GC). All
Scheme data objects share some common configuration (called "cells"):
They are 8-byte aligned; they reside is specially-allocated memory segments
(called hplims); they are the size of two pointers (so a scheme cons is
exactly a cell); and they contain a special GC bit used by the garbage
collector. This bit is 0 during actual computations. When a new cell is
needed and all the hplims are used, garbage collection is initiated. If
it does not free enough space to pass a certain threshold, a new hplim
is allocated.
The first stage in garbage collection is marking all cells which are
not to be deleted. Some terminology might be helpful here:
Obviously, all unreachable data is dead. Conservative garbage collectors
treat all reachable data as alive.
The Mark stage of the garbage collector scans the sys_protects[]
array and the machine's stack and registers for anything that looks like
a valid cell. All cell pointer have their 3 least significant bits zero,
and are in one of few known ranges (the hplims). The garbage collector
searches for anything matching a cell's bit pattern, and treats it as an
immediately reachable cell pointer. In some cases, this may mean an integer,
for example, happens to match the binary pattern and thus be interpreted
as a cell pointer. However, this will only mean some cell or cells are
marked as reachable though they are not such. Because of the uniform structure
of the cell and its limited range of possible locations, such an accident
is guarantied not to corrupt memory. Furthermore, if we accept the assumption
that integers are usually relatively small, and memory addresses are relatively
big, we conclude that such accidents are not very likely to happen often
anyway.
During mark stage, the garbage collector recursively finds (a superset
of) all live cells, and marks them by setting their special GC bit to 1.
The second stage is the Sweep stage, in which all the hplims are scanned
linearly, and every cell which is not marked is recognized as dead, and
as such is reclaimed as free. Marked cells get unmarked so they are ready
for the next garbage collection.
Mark & Sweep garbage collection has two main disadvantages: One,
that it requires all computation to stop while garbage collection is in
progress. In Galapagos, since all threads use a shared memory heap, it
means all threads must synchronize and halt while garbage is collected.
Second, Mark & Sweep is very likely to cause memory fragmentation.
However, since cells are equally sized, fragmentation is only rarely a
problem.
We chose to stick with Mark & Sweep in Galapagos because of its
two major advantages: Simplicity and efficiency. Mark & Sweep GC does
not affect computation speed, because direct pointers are used. Most concurrent
garbage collectors work by making all pointers indirect, which may slow
computations down considerably. The need to halt all threads for GC is
accepted. Since memory is shared, it would only be fair to stop all threads
when GC is needed: Threads will probably halt anyway since cells are allocated
continuously during computations.
Two major issues are introduced when trying to multithread the garbage
collector. One is the synchronization of the different threads, which run
almost completely unaware one of the other; the second is the need to mark
data from every thread's specific stack, registers, and sys_protects[].
We solved these two issues by combining them to one.
The intuitive approach might be to let each thread mark its own information,
and then sweep centrally. However, since synchronization of threads is
mandatory, letting every thread mark its own data will lead only to redundant
marking and to excessive context switches, since each threads has to become
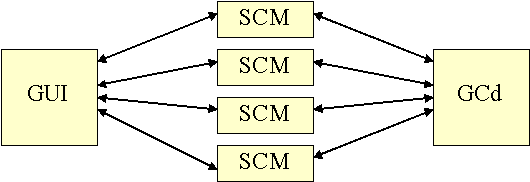
active. Therefore we created the "Garbage Collection daemon"
(GCd), which runs in a distinct thread and lasts for the whole Galapagos
session. The GCd is not an interpreter, but a mechanism which keeps track
of live threads and their need of GC. The GCd thread is always blocked,
except when a thread notifies it on its birth or death, or when a thread
indicates the need for garbage collection. Since the GC daemon is blocked
whenever it is not needed, and then becomes the exclusive running thread
during actual GC (with the exception of the GUI thread), its existence
does not hurt performance.
To explain how the GCd synchronizes all threads, let us examine the
three-way protocol involved. freelist
is a global pointer which holds a linked list of free cells - it can be
either a cell pointer, a value indicating "busy" (thus implementing
busy/wait protection over it) or "end of memory" which is found
at the end of the linked list. MIB stands for Memory Information
Block, which is a block of memory containing all of a thread's
immediately reachable data.
GCd scenario: GCd is blocked until a threads sends a GC request.
Scenario 1: A thread needs to allocate a cell but can't.
Scenario 2: A thread receives a MIB request. This may happen within a computation or when considered otherwise blocked - waiting for input, for example.
The important thing to note about this protocol is its indifference
to the GC "initiator". Several threads can "initiate"
GC, and each request is "satisfied", although of course only
one GC takes place. The GCd itself is unaware of the initiating thread
identity, and completely ignores any further GC requests. It treats all
threads identically. This is important because it allows each thread meeting
a low memory condition to initiate GC immediately. This is in fact the
mechanism which saves us from explicitly checking for a third-party GC
request during computation: If a thread runs out of memory, the freelist
variable is kept at "out of memory" state, causing any other
thread trying to allocate memory to initiate GC as well. This simplifies
the GC protocol (technically, if not conceptually), and does it with almost
no affect on computation speed.
A board or a view as it called in MFC is the environment where a turtle
moves and interact with. It hold two main data structures. The first is
the bitmap of the drawing. It is a 800X600 bitmap. Every time a turtle
draws on the board it makes its pen the active pen on the board and draws
on it. Every time the picture needs refreshing (as signaled by the operating
system) it is the board's duty to copy the relevant section from the bitmap
to the screen. The second data object is the turtles list, an expandable
array of turtles which holds pointers to all turtles on the specific board.
The most important part in the board's work is to notify the turtles
on any event that happened on the board such as drawing, changing background
or moving of a turtle. If for example a user draws a line on the board,
the board (after drawing the line) goes through the turtles list and tell
each one that some event happened at a rectangle that contains the line.
Each turtle will decide if this has any importance to it or not.
Apart from that, the board handles all the user interface from the menus
and the toolbar. The most obvious example is the move turtle button, which,
when pressed, causes the board to find a turtle close enough to the click's
location. Then, on every movement of the mouse it gives the turtle a command
to move to this point.
In order to support scrolling of the picture, we derived the CBoardView
class from CScrollView. The interface with the interpreter threads
is done via a message queue. The main function is ReadAndEval,
which gets a message and then interprets its and act upon the result.
In addition to a pointer to its current board, and to inner-state variable
which affects its graphical aspects, every turtle holds an expandable array
of interrupts. When a turtle gets from the window that a message signifying
that some change has happened, it sends this change to each of its interrupts
(only if the interrupt flag is on) and the interrupt is responsible to
send an appropriate message if necessary. The turtle's location are stored
as floating points on x,y axes, to allow for accuracy on the turtle's location
and heading.
The turtles interacts with the interpreter thread using a message queue.
As with the board, the main function here is the ReadAndEval,
which translates these messages to valid function calls.
Every turtle holds a pointer to the bitmap it is drawing on. When it
is "looking" for a color it calculates the minimal rectangle
that holds the desired area. Then it iterates on all the pixels in this
rectangle. First it checks if the pixel is in the vision area using the
sign rule to determine if a point is clockwise or anti clockwise from a
line, and then check for distance. If the point is in the relevant area
the turtle gets its color from the bitmap and compares it with the sought
color.
When looking for a specific turtle, the turtle gets this turtle's position
and calculates if this location is in the relevant area using the same
algorithm. When looking for any turtle, the turtle passes the relevant
arguments to the view, which then uses the same algorithm for each turtle
on its turtles array.
Each turtle holds an expandable array of interrupts. Each interrupts
is an object that is much like a turtle vision. The interrupts has the
view area argument and what it is looking for. It also has the message
it needs to send and a pointer to the given queue. When the turtle notifies
the interrupt that a change has happened, the interrupt first checks if
the change is an area which is of interest to it. If so it calls the turtle
look function with its location and the sought object. According to the
turtle's answer and to the data stored inside the interrupt, the interrupt
sends the needed message, if any.
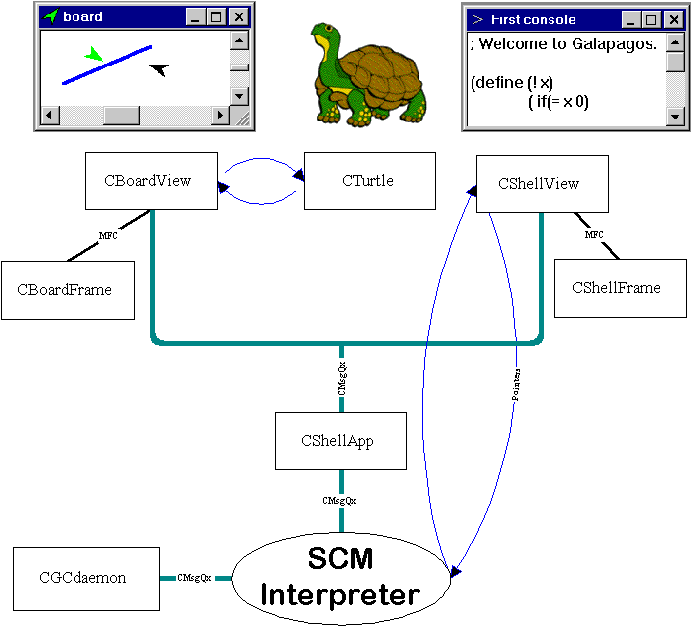
Message-passing mechanisms:
![[TOP]](back.gif)